MIT6.828-Lab2
Introduction
Memory management has two components, one is a physical memory allocator for the kernel, (which operate in units of 4KB, called pages), the other is virtual memory which maps the virtual addresses to addresses in physical memory.
Part1: Physical Page Management
a glimpse into Lab1
- we will map the entire bottom
256MBof the PC’s physical address space, from physical addresses0x00000000through0x0fffffff, to virtual addresses0xf0000000through0xffffffffrespectively Base Memorymeans the address from0x00000to0x9FFFFwhich contains640KBdue to the backward compatiability,Extended Memorydescribed itself.
Exercise 1

why JOS detects 128MB physical RAM?
by default QEMU emulates 128MB mem
some explanation about FUNC:mem_init
1 | |
the code above will insert a page directory item into pgdir, which points to the physical address that pgdir belongs to.
implementation
FUNC:boot_alloc: afterFUNC:page_alloccompleted, this function should never be called. So, the allocation forARRAY:pagesshould be done byboot_alloc, not bymalloc.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31static void *
boot_alloc(uint32_t n)
{
static char *nextfree; // virtual address of next byte of free memory
char *result;
// Initialize nextfree if this is the first time.
// 'end' is a magic symbol automatically generated by the linker,
// which points to the end of the kernel's bss segment:
// the first virtual address that the linker did *not* assign
// to any kernel code or global variables.
if (!nextfree) {
extern char end[];
nextfree = ROUNDUP((char *) end, PGSIZE);
}
// Allocate a chunk large enough to hold 'n' bytes, then update
// nextfree. Make sure nextfree is kept aligned
// to a multiple of PGSIZE.
//
// LAB 2: Your code here.
result = nextfree;
if(n > 0){
nextfree += ROUNDUP(n, PGSIZE);
}
if((uint32_t)nextfree > KERNBASE + npages * PGSIZE){
panic("out of memory\n");
}
return result;
}FUNC:page_init: we should know that memberpp_linkshould be NULL if that page already used. About section 4 below, useboot_alloc(0)to get the first free virtual address inExtended Memory.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45void
page_init(void)
{
// The example code here marks all physical pages as free.
// However this is not truly the case. What memory is free?
// 1) Mark physical page 0 as in use.
// This way we preserve the real-mode IDT and BIOS structures
// in case we ever need them. (Currently we don't, but...)
pages[0].pp_link = NULL;
pages[0].pp_ref = 1;
// 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE)
// is free.
size_t i;
for(i = 1; i < npages_basemem; i++){
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
// 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must
// never be allocated.
for(i = IOPHYSMEM / PGSIZE; i < EXTPHYSMEM / PGSIZE; i++){
pages[i].pp_link = NULL;
pages[i].pp_ref = 1; // i'm not certain
}
// 4) Then extended memory [EXTPHYSMEM, ...).
// Some of it is in use, some is free. Where is the kernel
// in physical memory? Which pages are already in use for
// page tables and other data structures?
for(i = EXTPHYSMEM / PGSIZE; i < PADDR(boot_alloc(0)) / PGSIZE; i++){
pages[i].pp_link = NULL;
pages[i].pp_ref = 1; // i'm not certain
}
cprintf("used %d pages\n", i - EXTPHYSMEM / PGSIZE);
for(i = PADDR(boot_alloc(0)) / PGSIZE; i < npages; i++){
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}FUNC:page_alloc: allocate single page.1
2
3
4
5
6
7
8
9
10
11
12
13
14struct PageInfo *
page_alloc(int alloc_flags)
{
if(!page_free_list){
return NULL;
}
int pages_idx = page_free_list - pages;
if(alloc_flags & ALLOC_ZERO){
memset(page2kva(page_free_list), '\0', PGSIZE);
}
page_free_list = page_free_list->pp_link;
pages[pages_idx].pp_link = NULL;
return &pages[pages_idx];
}FUNC:page_free: return a page to the free list1
2
3
4
5
6
7
8
9void
page_free(struct PageInfo *pp)
{
if(pp->pp_ref != 0 || pp->pp_link != NULL){
panic("this page should not be free now\n");
}
pp->pp_link = page_free_list;
page_free_list = pp;
}
Results
‘cause FUNC:page_insert not completed, so there was an assertion failed below.

Part2: Virtual Memory
Virtual, Linear, and Physical Addresses
A virtual address consists of a segment selector and an offset within the segment. A linear address is what you get after segment translation but before page translation. A physical address is what you finally get after both segment and page translation and what ultimately goes out on the hardware bus to your RAM.
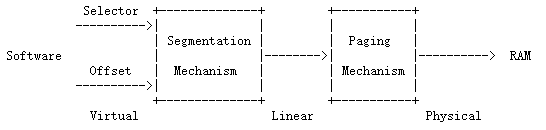
In boot/boot.S, we installed a Global Descriptor Table (GDT) that effectively disabled segment translation by setting all segment base addresses to 0 and limits to 0xffffffff. Hence the “selector” has no effect and the linear address always equals the offset of the virtual address. In lab 3, we’ll have to interact a little more with segmentation to set up privilege levels, but as for memory translation, we can ignore segmentation throughout the JOS labs and focus solely on page translation.
Exercise 3

- after
relocatedbyentry.S, usexp/x 0x100034andxp/x 0xf0100034inQEMU monitor, and usex/x 0xf0100034ingdb, result showed here.
- results in
QEMU monitor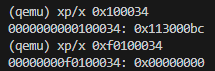
- results in
gdb
Exercise 4
For this part, the most important thing is to read Page Translation very carefully
FUNC:pgdir_walk
this function returns a pointer(linear address) to the page table entry(PTE) for linear address(la), when the page table where PTE in not exists, and PARAMETER:create decides whether to allocate a new page for the page table.
WARNING!!! here are serveral things to do before write this function.
- always keep this figure below in your mind. And the value of
PDEandPTEboth are physical address in order to translate the virtual address to physical address faster.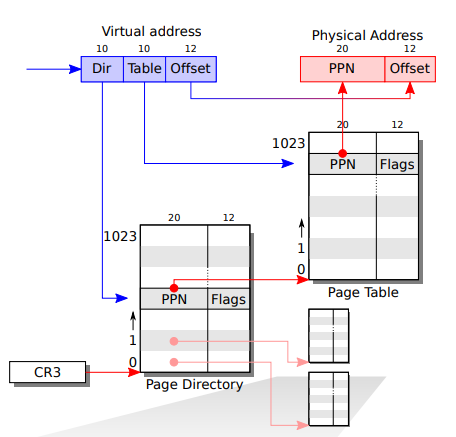
- read
inc/mmu.huntil you understandPTE_ADDR - read Page-Level Protection, make sure to fully understand
PTE_U,PTE_W, note thatPTE_Waffects both user and kernel.
code here, make sure to givePTE_WtoPDE, otherwise you can not write anything to pages, which will be tested by*(uint32_t *)PGSIZE = 0x03030303U;atFUNC:check_page_installed_pgdir1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26pte_t *
pgdir_walk(pde_t *pgdir, const void *la, int create)
{
pte_t *pt;
pgdir = &pgdir[PDX(la)];
if(*pgdir & PTE_P){
pt = (pte_t *)KADDR(PTE_ADDR(*pgdir));
return &pt[PTX(la)];
}
else if(!(*pgdir & PTE_P) & !create){
return NULL;
}
else{
struct PageInfo *newPT = page_alloc(ALLOC_ZERO);
if(newPT == NULL){
return NULL;
}
else{
// the free pages are writable to users
*pgdir = page2pa(newPT) | PTE_U | PTE_P | PTE_W;
newPT->pp_ref++;
return (pte_t *)page2kva(newPT) + PTX(la);
}
}
}
FUNC:page_lookup
this function returns the page mapped at linear address la. one thing to remeber is that conditions pte == NULL and *pte == 0, they both indicate no page mapped at la.
1 | |
FUNC:page_remove
this function unmaps the physical page at linear address la, just need to use FUNC:page_lookup to complete it.
1 | |
FUNC:page_insert
this function maps the physical page pp at linear address 1a. The corner case mentioned in comment can be solved by incrementing pp_ref before page_remove which will prevent page from being freed.
1 | |
results
Part3: Kernel Address Space
[ULIM,): user environment has no permission to this region, while the kernel can read and write this region.[UTOP,ULIIM): both the kernel and the user environment have the same permission, they can read but not write this region, this range of address is used to expose certain kernel data structures read-only to the users.[0,UTOP): for the user environment to use.
Exercise 5

FUNC:boot_map_region
1 | |
part of FUNC:mem_init
1 | |
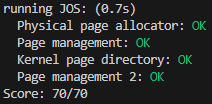
results
Question
- Draw the Page directory as much as possible.
- page directory itself is mapped at virtual address UVPT, means
PDX(UVPT)th entry in page directory points to page directory itself. - page info array is mapped at UPAGES, means
PDX(UPAGES)th entry in page directory points to page info array. - kernel stack is mapped at KSTACKTOP - KSTKSIZE, means
PDX(KSTACKTOP - KSTKSIZE)th entry in page directory points to kernel stack. - not to mention KERNBASE
- We have placed the kernel and user environment in the same address space. Why will user programs not be able to read or write the kernel’s memory? What specific mechanisms protect the kernel memory?
By usePTE_U - What is the maximum amount of physical memory that this operating system can support? Why?
according to page directory, the maximum amount of physical memory is4GB - How much space overhead is there for managing memory, if we actually had the maximum amount of physical memory? How is this overhead broken down?
1 page direstory + 1024pages + PageInfo array = 4KB + 4 * 1024KB + 8192KB = 12292KB - Revisit the page table setup in kern/entry.S and kern/entrypgdir.c. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP above KERNBASE? What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP above KERNBASE? Why is this transition necessary?
mentioned in Lab1, after execute code below‘cause it already maps virtual addresses [0, 4MB) to physical addresses [0, 4MB) in1
2
3
4mov $relocated, %eax
f0100028: b8 2f 00 10 f0 mov $0xf010002f,%eax
jmp *%eax
f010002d: ff e0 jmp *%eaxentrypgdir.c.