MIT6.828-Lab5
Introduction
In this lab, you will implement spawn, a library call that loads and runs on-disk executables. You will then flesh out your kernel and library operating system enough to run a shell on the console. These features need a file system, and this lab introduces a simple read/write file system.
File system preliminaries
This file system will provide the basic features: creating, reading, writing, and deleting files organized in a hierarchical directory structure. But does not support the UNIX notions of file owenership or permissions, and also doe not support hard links, symbolic links, time stamps, or special device files like most UNIX file systems do.
On-Disk File System Structure
Since our file system will not support hard links, we do not need this level of indirection and therefore can make a convenient simplification: our file system will not use inodes at all and instead will simply store all of a file’s (or sub-directory’s) meta-data within the (one and only) directory entry describing that file.
The file system environment handles all modifications to directories internally as a part of performing actions such as file creation and deletion. Our file system does allow user environments to read directory meta-data directly (e.g., with read), which means that user environments can perform directory scanning operations themselves (e.g., to implement the ls program).
Sectors and Blocks
Most disks cannot perform reads and writes at byte granularity and instead perform reads and writes in units of sectors. Be wary of the distinction between the two terms: sector size is a property of the disk hardware, whereas block size is an aspect of the operating system using the disk.
Most modern file systems use a larger block size, however, because storage space has gotten much cheaper and it is more efficient to manage storage at larger granularities. Our file system will use a block size of 4096 bytes, conveniently matching the processor’s page size.
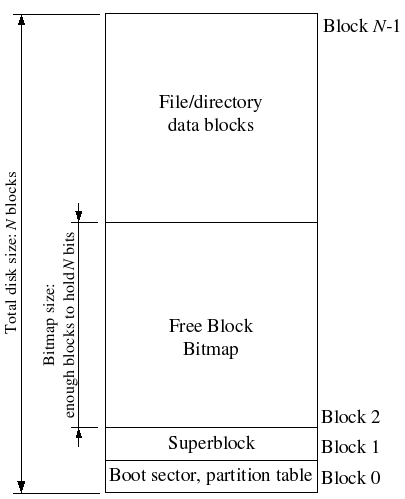
Superblocks
Block 0 is typically reserved to hold boot loaders and partition tables, so file systems generally do not use the very first disk block. Many “real” file systems maintain multiple superblocks, replicated throughout several widely-spaced regions of the disk, so that if one of them is corrupted or the disk develops a media error in that region, the other superblocks can still be found and used to access the file system.
File Meta-data
1 | |
The File System
The goal for this lab is not to have you implement the entire file system, but for you to implement only certain key components. In particular, you will be responsible for reading blocks into the block cache and flushing them back to disk; allocating disk blocks; mapping file offsets to disk blocks; and implementing read, write, and open in the IPC interface.
Disk Access
In JOS, instead of taking the conventional “monolithic” operating system strategy of adding an IDE disk driver to the kernel along with the necessary system calls to allow the file system to access disk, we instead implement the IDE disk driver as part of the user-level file system environment.
So we have two strategies to implement disk access in user space, one is relyong on polling, “programmed I/O” (PIO)-based disk access and do not use disk interrupts, the other is implementing interrupt-driven device drivers in user mode, it needs the kernel field device interrupts and dispatch them to the correct user-mode environment. JOS chooses the former.
The x86 processor uses the IOPL bits in the EFLAGS register to determine whether protected-mode code is allowed to perform special device I/O instructions such as the IN and OUT instructions. Since all of the IDE disk registers we need to access are located in the x86’s I/O space rather than being memory-mapped, giving “I/O privilege” to the file system environment is the only thing we need to do in order to allow the file system to access these registers. In effect, the IOPL bits in the EFLAGS register provides the kernel with a simple “all-or-nothing” method of controlling whether user-mode code can access I/O space. In our case, we want the file system environment to be able to access I/O space, but we do not want any other environments to be able to access I/O space at all.

Details of IOPL

resoluton here:
1 | |
The Block Cache
In our file system, we will implement a simple “buffer cache” (really just a block cache) with the help of the processor’s virtual memory system.
We reserve a large, fixed 3GB region of the file system environment’s address space, from 0x10000000 (DISKMAP) up to 0xD0000000 (DISKMAP+DISKMAX), as a “memory mapped” version of the disk.
Of course, it would take a long time to read the entire disk into memory, so instead we’ll implement a form of demand paging, wherein we only allocate pages in the disk map region and read the corresponding block from the disk in response to a page fault in this region.

resolution here:
1 | |
The Block Bitmap

1 | |
File Operations
file_block_walk and file_get_block are the workhorses of the file system. For example, file_read and file_write are little more than the bookkeeping atop file_get_block necessary to copy bytes between scattered blocks and a sequential buffer.

Solution here, note that *ppdiskbno modified by file_block_walk may be zero, and remeber to flush_block after clear block cache.
1 | |
The file system interface
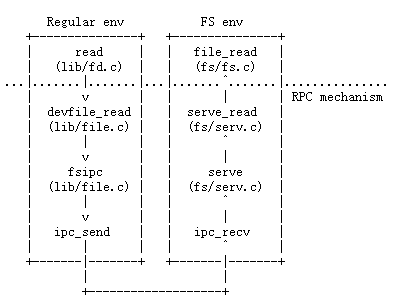
Now that we have the necessary functionality within the file system environment itself, we must make it accessible to other environments that wish to use the file system. Since other environments can’t directly call functions in the file system environment, we’ll expose access to the file system environment via a remote procedure call, or RPC, abstraction, built atop JOS’s IPC mechanism. Graphically, here’s what a call to the file system server (say, read) looks like:
Exercise 5 & 6
1 | |
Spawning Process

code here:
1 | |
Sharing library state across fork and spawn
File descriptor state is kept in user-space memory. On fork, this memory will be marked copy-on-write, so the state will be duplicated rather than shared. On spawn, the memory will be left behind, not copied at all.
We will change fork and spawn to know that certain regions of memory are used by the “library operating system” and should always be shared.

My code here:
1 | |
The keyboard interface
Use the keyboard and serial drivers already implemented, to handle trap keyboard interrupt and serial interrupt.
1 | |