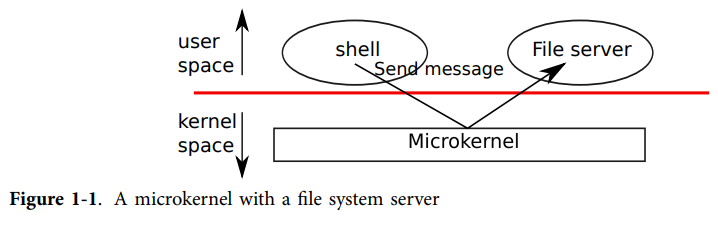
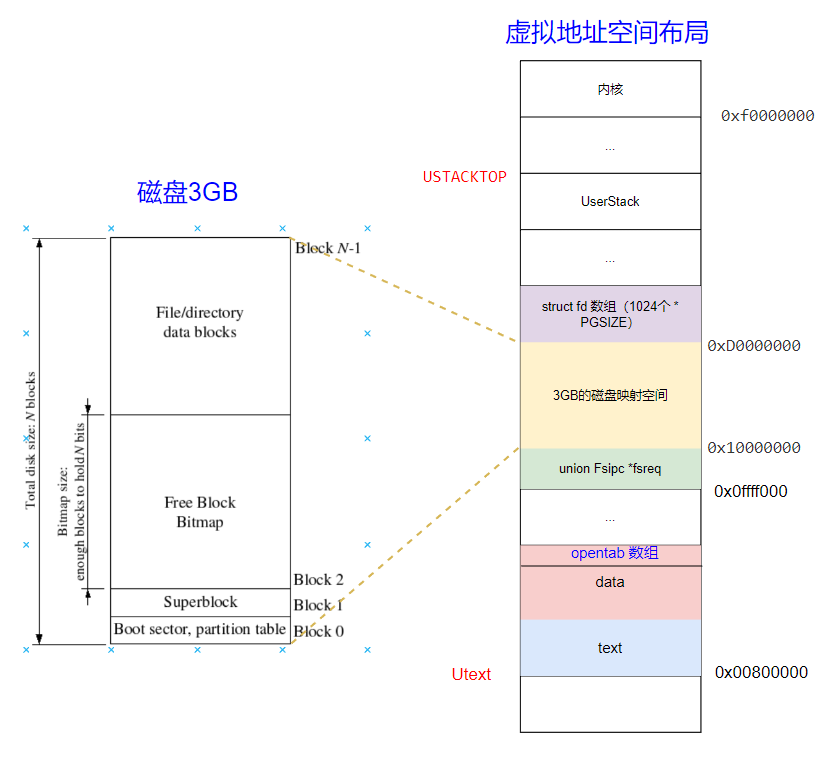
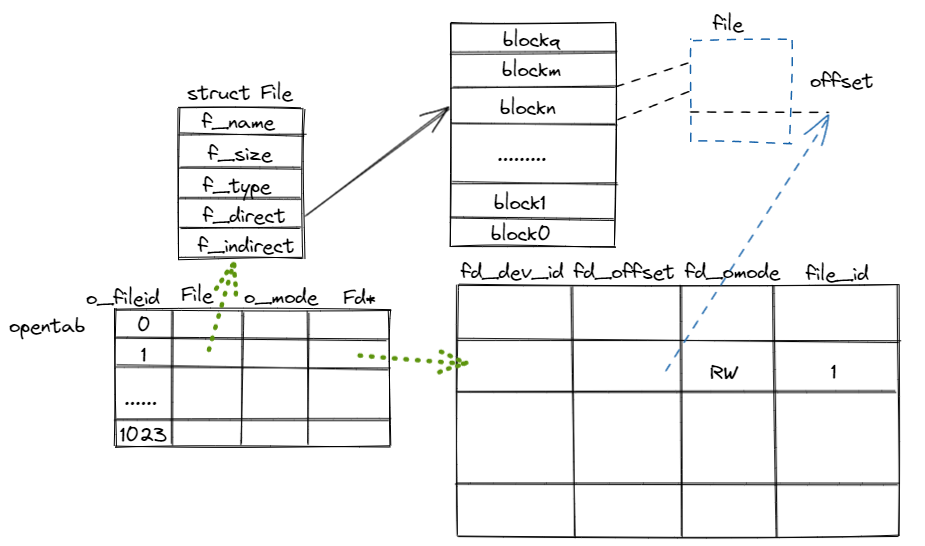
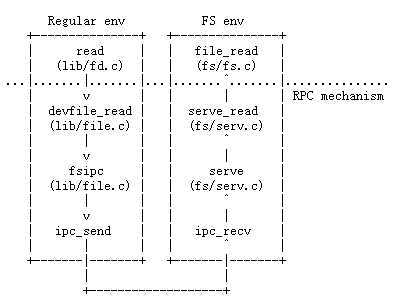
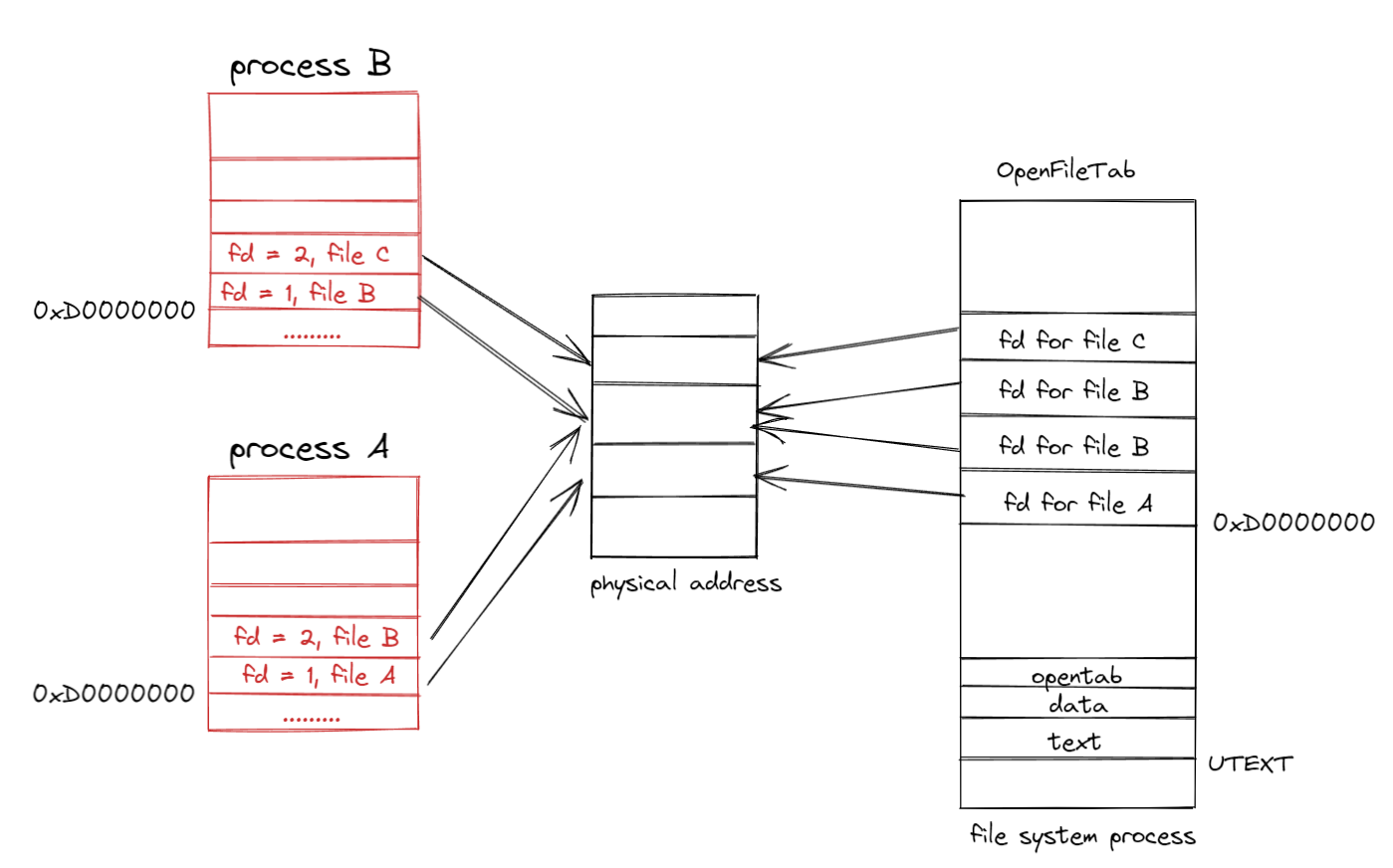
structFdFile { int id; }; structFd { int fd_dev_id; off_t fd_offset; int fd_omode; union { // File server files structFdFilefd_file; }; }; structOpenFile { uint32_t o_fileid; // file id 与文件并不是一一对应的,主要的作用就是找到Fd对应的OpenFile structFile *o_file;// mapped descriptor for open file int o_mode; // open mode structFd *o_fd;// Fd page };
// lib/entry.S // Entrypoint - this is where the kernel (or our parent environment) // starts us running when we are initially loaded into a new environment. .text .globl _start _start: // See if we were started with arguments on the stack cmpl $USTACKTOP, %esp jne args_exist
// If not, push dummy argc/argv arguments. // This happens when we are loaded by the kernel, // because the kernel does not know about passing arguments. pushl $0 pushl $0
args_exist: call libmain 1: jmp 1b
// lib/libmain.c void libmain(int argc, char **argv) { // set thisenv to point at our Env structure in envs[]. // LAB 3: Your code here. thisenv = &envs[ENVX(sys_getenvid())];
// save the name of the program so that panic() can use it if (argc > 0) binaryname = argv[0];
// devpipe_read for (i = 0; i < n; i++) { while (p->p_rpos == p->p_wpos) { // pipe is empty // if we got any data, return it if (i > 0) return i; // if all the writers are gone, note eof if (_pipeisclosed(fd, p)) return0; // yield and see what happens if (debug) cprintf("devpipe_read yield\n"); sys_yield(); } // there's a byte. take it. // wait to increment rpos until the byte is taken! buf[i] = p->p_buf[p->p_rpos % PIPEBUFSIZ]; p->p_rpos++; } // devpipe_write for (i = 0; i < n; i++) { while (p->p_wpos >= p->p_rpos + sizeof(p->p_buf)) { // pipe is full // if all the readers are gone // (it's only writers like us now), // note eof if (_pipeisclosed(fd, p)) return0; // yield and see what happens if (debug) cprintf("devpipe_write yield\n"); sys_yield(); } // there's room for a byte. store it. // wait to increment wpos until the byte is stored! p->p_buf[p->p_wpos % PIPEBUFSIZ] = buf[i]; p->p_wpos++; }
staticint _pipeisclosed(struct Fd *fd, struct Pipe *p) { int n, nn, ret;
while (1) { n = thisenv->env_runs; ret = pageref(fd) == pageref(p); nn = thisenv->env_runs; if (n == nn) return ret; if (n != nn && ret == 1) cprintf("pipe race avoided\n", n, thisenv->env_runs, ret); } }